




TABLE OF CONTENTS
Experience the Future of Speech Recognition Today
Try Vatis now, no credit card required.
A support team rolls out automatic transcription for customer calls. A newsroom turns on auto captions for fast video publishing. A legal team starts indexing recorded meetings so staff can search them later.
At first, the results look promising. Then the friction shows up.
Agents search for a complaint phrase and miss it because the transcript used the wrong word. Producers spend extra time fixing subtitles before a clip can go live. Reviewers lose confidence because names, dates, or product terms keep coming back wrong. The transcript exists, but the team still cannot rely on it.
That is where word error rate becomes useful. It gives you a common way to measure how far a transcript is from a trusted reference, and it helps you diagnose what kind of mistakes your system is making, where they come from, and whether they matter for your use case.
If you are a product manager, word error rate helps you turn “the transcript feels off” into something measurable. If you are a developer, it helps you compare models, test preprocessing choices, and decide what to fix first. If you run operations in media, legal, healthcare, or contact centers, it helps you separate acceptable automation from risky automation.
Why Inaccurate Transcripts Hurt Your Business
Transcript errors do not stay inside the transcript. They spread into search, analytics, compliance, and customer experience.
A contact center team might use transcripts to find refund requests, escalations, or churn signals. If the model drops key words or swaps them for near-matches, the analytics layer starts from bad input. Teams then make decisions based on incomplete evidence.
A broadcaster or newsroom feels the pain differently. Auto captions save time only if editors can trust the first draft. When the transcript is noisy, producers still have to review every line, which turns automation into another editing queue instead of a speed advantage.
Where the damage shows up
- Search breaks first: Users search for spoken phrases that never made it into the transcript.
- Summaries drift: If the source text is wrong, downstream summarization can confidently describe the wrong thing.
- Compliance risk rises: In legal or healthcare workflows, a small wording error can change meaning in a way that matters.
- Team adoption drops: Once reviewers stop trusting transcripts, they stop using them for decisions.
Consider two transcript failures.
In one, the system inserts a few filler words. The transcript looks messy, but a reviewer still understands it. In another, it changes a medication name, a person’s surname, or the word “approved” to something else. Both are “errors,” but the second kind has a much bigger business impact.
Key takeaway: The cost of inaccurate speech recognition is rarely the transcript alone. It is the manual review, missed insights, and broken downstream workflows that follow.
The practical lesson is simple. Before you improve anything, you need a way to measure accuracy consistently. That is the role of word error rate.
What Is Word Error Rate Explained
Think of an ASR transcript as a rough draft and a human-checked transcript as the final copy. Word error rate, or WER, measures how much editing it would take to turn the rough draft into the final one.
The standard formula is WER = (S + D + I) / N × 100%, where S is substitutions, D is deletions, I is insertions, and N is the number of words in the reference transcript. It is widely used as the core metric for automatic speech recognition evaluation, and its modern use as a benchmark took shape in the 1990s alongside advances in hidden Markov model based systems and standardized ASR evaluation practice, as summarized in this explanation of Word Error Rate. If you want the broader mechanics behind transcription models, this step by step guide to the ASR pipeline is a useful companion.
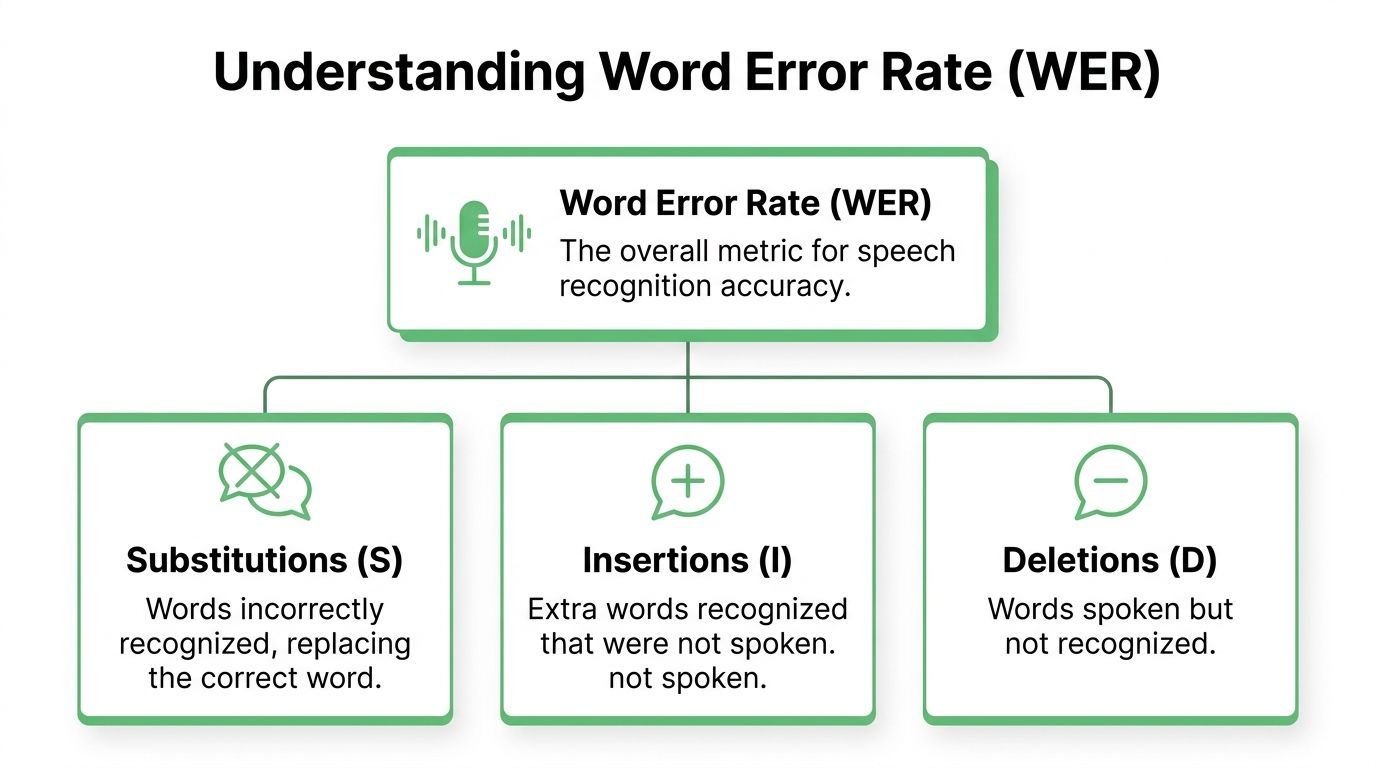
The three error types
Here is the easiest way to understand the parts of WER.
Substitution
The system heard a word, but chose the wrong one.
Example: “approve” becomes “improve.”Deletion
A spoken word is missing from the transcript.
Example: “send the contract today” becomes “send contract today.”Insertion
The transcript adds a word that no one said.
Example: “we agree” becomes “we do agree.”
What WER measures
WER does not measure meaning directly. It measures word-level mismatch between two texts.
That distinction matters. A transcript can have a decent WER and still fail on the one word your workflow depends on. It can also have a weaker WER while staying usable for search or summary if the errors are minor.
A simple mental model
If the reference transcript has ten words, and the ASR output contains one substitution and one deletion, the system made two word-level errors across ten reference words. That means the transcript needs noticeable repair.
The focus on the reference transcript is where many beginners get confused. The denominator is not the number of words the model produced. It is the number of words in the ground-truth transcript. That is also why WER can go above 100% when insertions pile up.
Practical tip: Treat WER as a disciplined editing estimate. It tells you how much the transcript differs from what was said, not whether the output is “good enough” for your exact product.
How to Calculate Word Error Rate Step by Step
Calculating word error rate by hand is the fastest way to understand what your evaluation script is doing.
Start with two transcripts:
- The reference, which is the trusted ground truth.
- The hypothesis, which is the ASR output.
Then align them word by word and count substitutions, deletions, and insertions.
Step 1 normalize before scoring
Before you compare anything, decide your normalization rules.
Teams often lowercase text, standardize formatting, and decide how to handle punctuation or numbers. This is useful because raw formatting differences can distort the score. But normalization can also hide problems if you make it too aggressive.
A good rule is to keep one evaluation setup fixed and document it clearly.
Step 2 align the two transcripts
You do not compare the strings by eye from left to right only. You align them in the way that produces the smallest valid edit path.
That alignment comes from Levenshtein-style edit distance. In practice, libraries do this for you. As an engineer, you still need to understand the output so you can debug it.
Step 3 count S D and I
Once aligned, count:
- Substitutions when one word replaces another
- Deletions when a reference word is missing
- Insertions when an extra word appears in the hypothesis
Worked examples
| Reference (N words) | Hypothesis | Errors (S, D, I) | Calculation | WER |
|---|---|---|---|---|
| The quick brown fox jumps over the lazy dog (9 words) | The quick brown fox jump over the lazy | (1, 1, 0) | (1 + 1 + 0) / 9 | 22.22% |
| please send the signed contract today | please send signed contract today now | (0, 1, 1) | (0 + 1 + 1) / N | Qualitatively, one deletion and one insertion over the reference length |
The first example is the classic one. “jumps” becomes “jump,” which is one substitution. “dog” disappears, which is one deletion. So the WER is 22.22%.
The second example shows why alignment matters. The model did not replace every later word. It dropped “the” and added “now.” A naive comparison can overcount errors if you do not align properly.
A practical review workflow
When you calculate WER for production evaluation, use this sequence:
Freeze the scoring rules
Decide on normalization once and reuse it.
Score a representative sample
Include the kind of audio you handle, not just clean clips.
Inspect examples with high WER
Look for patterns such as names, acronyms, crosstalk, or accents.
Break errors down by type
Heavy substitutions often suggest vocabulary or acoustic mismatch. Many deletions can point to overlap or dropped low-volume words. Insertions often appear in noisy audio.
Where people get tripped up
- They compare different scoring pipelines. Then the number looks scientific, but the comparison is not fair.
- They optimize one average score only. That can hide disastrous behavior on one critical subset of calls or meetings.
- They ignore the transcript examples. A score tells you how much error exists. The examples tell you why.
For PMs and developers, that last point holds significant value. WER is not only a report-card number. It is a debugging lens.
Interpreting Your WER Score What Is a Good Rate
A word error rate number without context is only half useful.
The same score can be excellent for one workflow and unacceptable for another. If your goal is rough topic detection in long media archives, you can tolerate more noise. If your goal is legal review or high-stakes customer analytics, the tolerance is much lower.
Benchmark numbers are real but conditional
Real-world benchmarks vary sharply by domain. Top systems reach 3% to 7% WER on clean Common Voice data, but rise to 9% to 14% on earnings calls. For business users, those gaps matter because they show how quickly clean benchmark performance can drift once audio becomes longer, denser, and more domain-specific, as described in this discussion of WER across real-world conditions.
The same source notes two practical thresholds that many teams recognize immediately:
- Broadcasters feel pain above 20% WER, because editing overhead can double.
- Contact centers often target below 5% WER when the transcript feeds critical analytics.
A business-first reading of the score
| Use case | What matters most | Practical reading of WER |
|---|---|---|
| Contact center analytics | Intent, entities, compliance phrases | Low WER matters because downstream analytics depend on exact wording |
| News and broadcast captions | Readability and edit speed | Moderate error can be manageable until editors lose speed |
| Legal and healthcare review | Names, facts, meaning, traceability | Raw WER is not enough on its own. Human review is often still required |
| Media monitoring and search | Retrieval and rough understanding | A transcript can still be useful even when it is not publication-ready |
Ask these questions instead of only asking what is good
- What is the transcript used for? Search, captioning, legal evidence, analytics, or summary all have different tolerances.
- Which words are mission-critical? Product names, medications, dates, and case references deserve special attention.
- What does a mistake cost? Editing time, missed signal, or compliance risk change the acceptable threshold.
Useful rule: Do not set one universal WER target across your company. Set targets by workflow.
That mindset keeps teams from chasing a single vanity score. The better question is whether the transcript is reliable enough for the action that follows.
The Limits and Pitfalls of Using WER
WER is useful, but it is not fair to every kind of transcript error.
The metric counts edits, not impact. A trivial article change and a dangerous semantic flip can both register as one substitution. For product teams, this is the biggest trap. A lower WER can still hide the error that breaks the user experience.

WER treats all words the same
Suppose a model changes “the contract” to “a contract.” That may not matter much in many workflows.
Now suppose it changes “safe” to “unsafe,” or misspells a proper noun that your search index depends on. Standard WER counts both as a single error. Humans do not.
This is one reason teams become frustrated when a model looks good in evaluation but feels worse in use.
Formatting can distort the score
Casing, punctuation, and number formatting are another source of confusion.
Apple’s work on Human Evaluation Word Error Rate, or HEWER, points out that traditional WER can over-penalize minor casing and punctuation differences, inflating scores by 20% to 46% above actual understanding accuracy. HEWER focuses on major errors that alter meaning or readability, which often maps better to how reviewers judge transcript quality in practice, as described in Apple’s discussion of Humanizing WER.
Common pitfalls in production
- Homophones: “their” and “there” may sound identical but have different downstream consequences.
- Disfluencies: Fillers and false starts can inflate WER even when the transcript remains understandable.
- Proper nouns: Names, brands, case citations, and medical terms carry more business value than function words.
- Punctuation decisions: One team strips punctuation before scoring, another keeps it. The reported WER changes even if the model does not.
When to use a second metric
If your workflow depends on readability, entity correctness, or decision-critical terms, pair WER with something else.
For example:
- readability review by human editors
- proper noun accuracy checks
- domain-specific entity evaluation
- HEWER-style review for meaning-changing errors
Practical tip: Use WER as the baseline metric, then add a second metric that reflects what failure looks like in your product.
That approach gives you a better signal than raw WER alone.
How to Reduce Your Word Error Rate
Most WER reduction work falls into three buckets. Improve the audio, improve the model’s vocabulary fit, and improve how you handle multi-speaker conversation.
For conversational speech, published references note that WER often lands in the 35% to 60% range because of interruptions and disfluencies. The same material also notes that custom vocabulary can reduce substitutions by 20% to 30% in legal and healthcare applications, while speaker diarization helps with overlap-induced errors, according to the Wikipedia summary of word error rate and practical factors that affect it. If your team is collecting audio in the first place, this guide on how to record domains for speech to text accuracy is worth reviewing.
Fix what happens before transcription
The cheapest quality gain often comes before the model runs.
Use better microphones when you can. Reduce room noise. Separate speakers clearly in remote recording setups. Avoid heavy compression if your pipeline allows cleaner audio capture. These steps do not sound glamorous, but they directly affect substitutions, deletions, and insertions.
Teach the system your language
General ASR models struggle with specialized terms.
Legal teams have case names and citations. Healthcare teams have medication names and clinician terminology. Media teams have recurring people, places, and program titles. If your platform supports custom vocabulary, use it. This is one of the most direct ways to reduce substitution errors on words your business cares about.
A strong setup often includes:
- Custom terms: product names, acronyms, surnames, and domain vocabulary
- Pronunciation-aware testing: especially for names that sound unlike their spelling
- Regular updates: because your vocabulary changes with clients, releases, and events
Handle speaker overlap on purpose
Many ugly transcripts come from one simple reality. People interrupt each other.
That is why speaker diarization matters. It separates who spoke when, which makes alignment cleaner and reduces confusion in overlapping speech. It also helps reviewers trust the transcript because the text is organized by speaker rather than collapsed into one stream.
Add post-processing carefully
Post-processing can help if it fixes recurring mistakes without changing meaning recklessly.
Examples include:
- correcting known brand names
- restoring preferred capitalization
- validating entities against a domain list
- formatting transcript output for subtitle or document export
One option teams use is Vatis Tech, which offers speech-to-text with custom vocabulary, speaker diarization, timestamps, entity extraction, and PII redaction for production workflows. The key point is not the brand. It is choosing a system that lets you tune the transcript around your domain instead of treating all audio as generic speech.
The most effective teams do not chase WER with one trick. They remove errors at the source, then tune for the words and speakers that matter most.
How Vatis Tech Delivers Industry-Leading Accuracy
Accuracy work in production usually comes down to fit. The model has to handle your audio conditions, your vocabulary, your speakers, and your compliance requirements.
Vatis Tech is built for that kind of workflow. It supports transcription in 50+ languages and provides 98%+ accuracy in its product description, along with features such as speaker diarization, timestamps, summaries, chapters, multilingual translation, entity extraction, and PII redaction. Those features matter because transcript quality is not only about raw recognition. It is also about how easily a team can review, structure, and use the output.
For engineering teams, API access and SDKs make it possible to test speech workflows against real business audio rather than only benchmark clips. For operations teams, the editable transcript and export formats help close the gap between machine output and publishable or auditable output.
If you want a closer look at model progress, Vatis Tech has also shared details about its V7 transcription model.
Frequently Asked Questions About WER
Can word error rate be more than 100 percent
Yes. WER can exceed 100% when insertions dominate, because the error count keeps growing while the denominator stays fixed at the number of words in the reference transcript.
Does punctuation count in WER
It depends on your evaluation pipeline. Some teams strip punctuation and lowercase everything before scoring. Others keep punctuation or even treat it as a token in more human-centered evaluations. What matters is consistency.
Is lower WER always better
Usually, but not always in the way users experience quality. A lower WER means fewer word-level mismatches. It does not guarantee better readability, better entity extraction, or fewer meaning-changing mistakes.
What is a good WER for legal or medical transcription
These are high-stakes domains, so teams usually need much stricter review standards than they would for general search or rough note-taking. In sensitive workflows, human verification is often still necessary even when the transcript quality looks strong.
Why does my benchmark WER look better than production
Because production audio is harder. Real conversations include overlap, disfluencies, inconsistent microphones, accents, and domain-specific terms. The score can shift a lot when those conditions change.
Should I use WER alone to choose a provider
No. Use WER as a baseline, then inspect transcript samples and check the errors that matter to your workflow. If names, codes, legal terms, or medical entities are critical, test those directly.
If you want to evaluate transcription quality on your own audio instead of generic benchmark clips, Vatis Tech gives teams a practical way to test speech-to-text in real workflows, from contact centers and media to legal and healthcare.




