




TABLE OF CONTENTS
Experience the Future of Speech Recognition Today
Try Vatis now, no credit card required.
You likely already have the problem.
Customer calls are recorded. Meetings live in Zoom or Teams. Webinars, interviews, hearings, consultations, podcasts, and internal training sessions pile up in cloud storage. Everyone knows there's useful information inside that audio and video, but almost none of it is searchable, reusable, or easy to audit.
That's where speech to text ai changes the operating model. It turns spoken content into structured text that teams can search, review, redact, summarize, route, and analyze. Once speech becomes text, it stops being a media file and starts becoming workflow data.
This isn't a niche tooling category anymore. The global speech-to-text API market was valued at USD 5.63 billion in 2026 and is projected to reach USD 25.28 billion by 2034, growing at a 20.66% CAGR, according to speech-to-text market projections summarized by Sonix. That kind of growth tells you something important. Buyers are no longer treating transcription as a convenience feature. They're treating it as infrastructure.
The Unstructured Data Problem You Need to Solve
Most organizations don't struggle with lack of data. They struggle with lack of usable data.
A support team may record thousands of customer interactions, but if those conversations stay locked in audio files, managers can't reliably review disclosure language, product complaints, escalation triggers, or coaching opportunities. A newsroom may have years of interviews and broadcasts, but producers still waste time scrubbing through footage manually. A clinic may document patient discussions, yet administrative teams still have to turn spoken detail into records by hand.
Audio is valuable but operationally invisible
The core issue is simple. Audio and video are rich in context, but they're poor inputs for normal business systems unless you transcribe them first.
Text is what your stack understands. Search tools index it. analytics systems classify it. compliance teams review it. legal teams preserve it. QA teams score it. Product teams feed it into downstream workflows.
That's why speech to text ai has become far more than a dictation feature. In practice, it acts as the first conversion layer between unstructured conversation and structured operations.
Practical rule: If a team needs to search, audit, summarize, redact, or measure spoken interactions at scale, transcription usually sits at the front of that workflow.
Where teams feel the pain first
The pressure usually shows up in a few familiar places:
- Customer operations: Supervisors need fast access to what was said, not just that a call happened.
- Media workflows: Editors need captions, quotes, and searchable archives without manual logging.
- Healthcare documentation: Staff need spoken content turned into usable records while preserving privacy controls.
- Legal and compliance review: Teams need traceable transcripts for evidence, review, and disclosure verification.
Speech to text ai matters because it enables these use cases without requiring people to listen back to everything manually. The value isn't just transcription output. The value is what the organization can finally do after the transcript exists.
The strategic shift
The teams that get the most from speech to text ai don't buy it as a standalone model benchmark. They adopt it as part of a broader information architecture.
That means asking different questions. Not “can it transcribe?” but “can it transcribe our calls, our accents, our jargon, our retention rules, and our review process?” Once you frame it that way, implementation choices become much clearer.
How Speech to Text AI Actually Works
Speech recognition feels magical until you break it into stages. Under the hood, the system is doing a sequence of pattern-matching and prediction tasks that are easier to evaluate once you know what each stage contributes.
Here's the basic process flow.
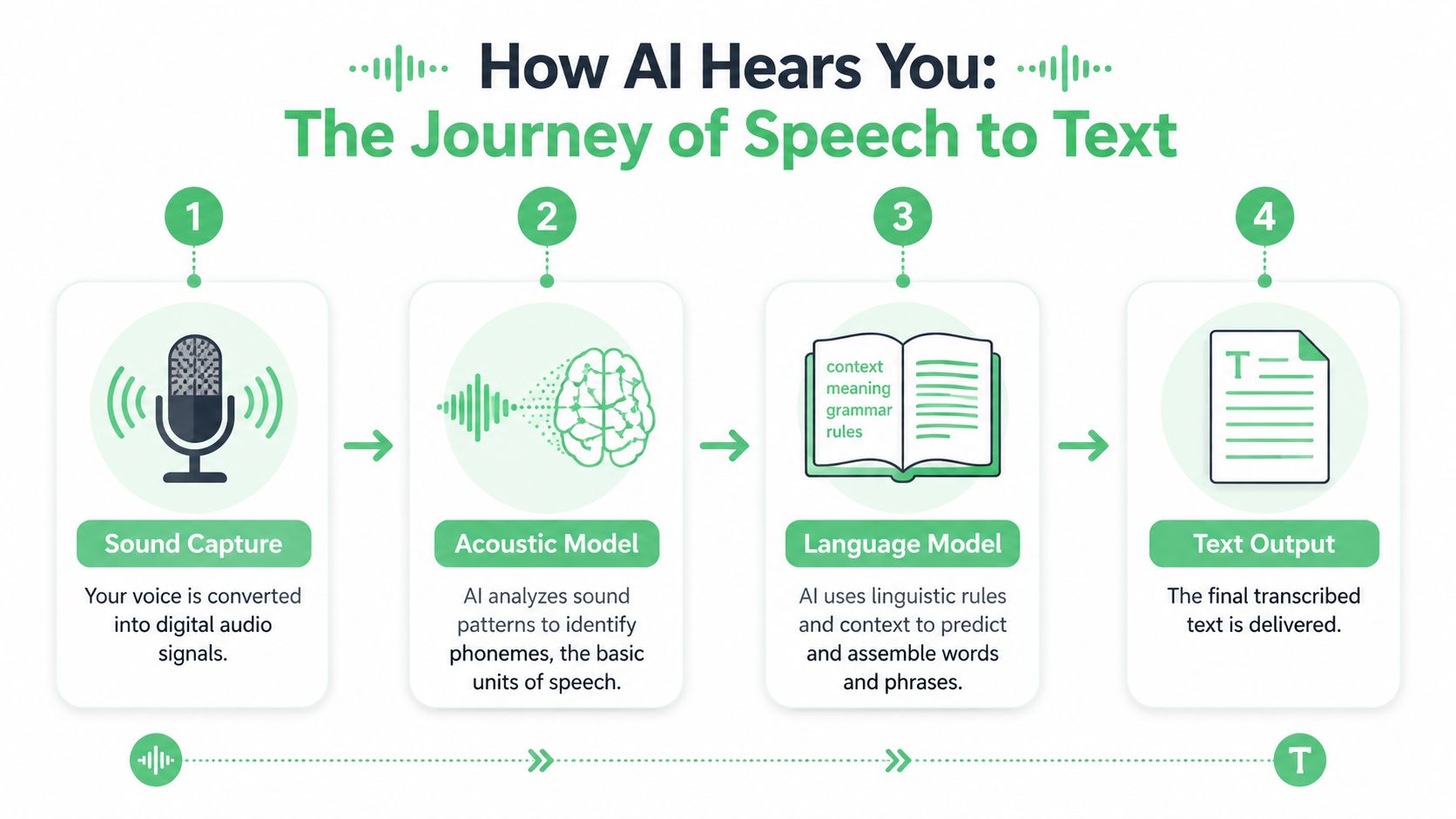
It starts with sound, not words
When someone speaks, the system doesn't receive “sentences.” It receives an audio signal.
The first job is to convert that signal into digital features the model can analyze. Think of this as the machine learning equivalent of hearing tone, rhythm, pauses, and sound shapes before understanding meaning. From there, the system looks for patterns that correspond to the smallest building blocks of speech.
A useful way to think about it is how humans learn language. First you hear sounds. Then you learn which sounds map to words. Then context tells you whether someone said one similar-sounding word or another.
For readers who want a more technical breakdown of the ASR pipeline, this step-by-step guide to how automatic speech recognition works is a solid companion reference.
The core models each solve a different problem
Most speech to text ai systems rely on several layers of modeling logic.
- Acoustic processing: The model analyzes the audio signal and identifies likely phonetic units. At this stage, microphone quality, background noise, compression artifacts, and speaker overlap start to matter.
- Pronunciation mapping: The system maps likely sound sequences to candidate words. If a speaker says a product name, surname, or acronym, this stage can fail unless the model has seen similar patterns before.
- Language modeling: Context helps the system decide which word sequence is most plausible. “Policy number” and “account number” create different expectations than a casual conversation or an interview transcript.
This is one reason domain performance varies so much. A model that handles podcasts well can still struggle in a financial call, a medical consult, or a legal hearing if the vocabulary and phrasing shift.
Later-stage machine learning choices matter too. If you want a grounding in supervised versus unsupervised approaches, TekRecruiter's explanation of key differences in machine learning is useful context for understanding why training data quality shapes transcription outcomes.
A short visual explainer helps if you're reviewing this with non-technical stakeholders:
Why context fixes some errors and creates others
Speech to text ai doesn't “hear” the way people do. It predicts.
That prediction process is powerful, but it also explains common failure modes. When the input is clean, the model can use both sound and context effectively. When the audio is noisy or the speaker uses unfamiliar terminology, the model may substitute a more probable word that sounds close enough.
A transcription error often isn't random. It's the system choosing the most statistically plausible interpretation from imperfect evidence.
That's why implementation teams should never treat transcription as a single black box. If you understand the pipeline, you can usually diagnose where performance is breaking down. Bad audio capture, weak vocabulary coverage, poor language context, and overlapping speakers leave different fingerprints in the output.
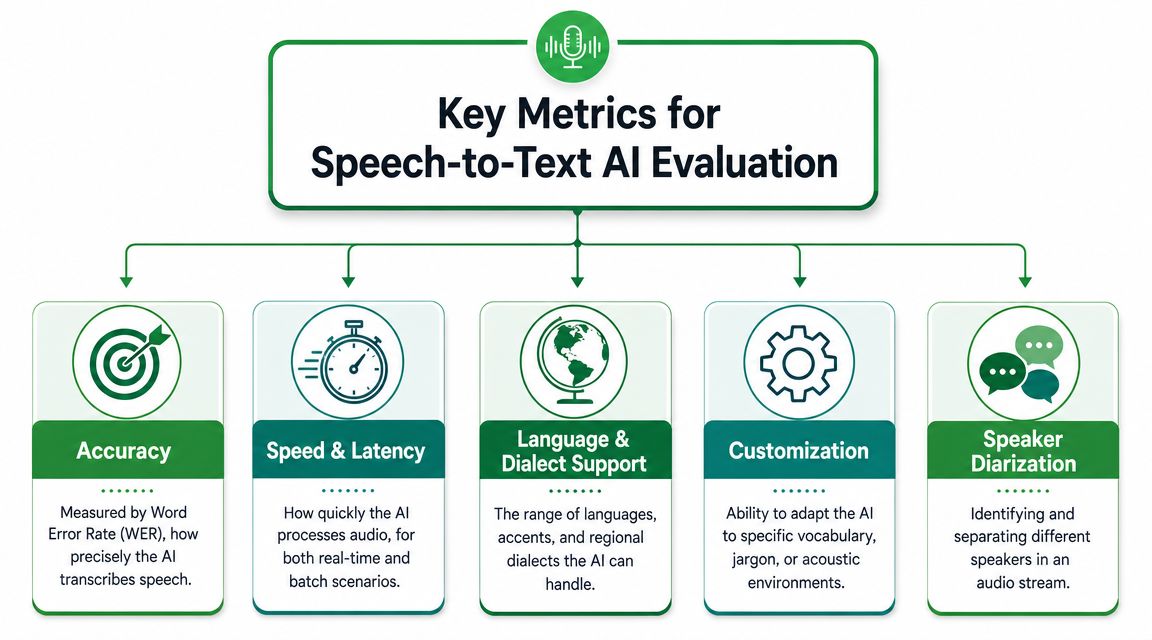
Evaluating Key Features and Performance Metrics
Most vendor comparisons start and end with accuracy. That's too narrow.
Modern speech recognition systems can achieve over 90% accuracy in optimal conditions, and benchmark tracking cited by AssemblyAI shows top providers posting Word Error Rates from 2.2% to 4.2%, including ElevenLabs and OpenAI models, while also noting that real-world performance depends heavily on audio quality, accents, and domain terminology in AssemblyAI's review of speech-to-text accuracy. That's useful context, but it won't tell you whether a tool will work for your calls, your meetings, or your compliance workflow.
Start with WER, then go wider
Word Error Rate, or WER, is still the standard metric. It measures how many words were inserted, deleted, or substituted compared with a reference transcript. If you need a plain-English breakdown, this guide on what WER means in speech-to-text is worth bookmarking.
But WER has limits. It treats all mistakes similarly, even though some errors are much more damaging than others.
A missed filler word may be harmless. A wrong account number, medication name, or legal entity can break the workflow. That's why practitioners should review not just overall error rate, but error type.
The features that actually change outcomes
A vendor can post strong benchmark numbers and still fail operationally if the rest of the stack is weak.
Here's what to inspect beyond raw accuracy:
| Feature | Why it matters in practice |
|---|---|
| Latency and speed | Real-time captioning, live agent assist, and meeting notes need fast output. Batch archives can tolerate slower processing. |
| Speaker diarization | If the system can't separate speakers reliably, QA review, interview editing, and legal analysis become harder. |
| Timestamps | Word-level or segment timing makes it possible to jump from transcript back to source media. |
| Language and dialect support | Global teams need more than nominal language coverage. They need consistent performance on actual speaker populations. |
| Custom vocabulary or domain adaptation | Industry terms, names, acronyms, and product codes are common failure points. |
| Editability | If users must heavily rewrite transcripts, benchmark quality doesn't translate into business value. |
Test the workflow, not just the model
The fastest way to make a poor buying decision is to test only on polished sample audio.
Use a mixed evaluation set instead:
- Clean recordings: Internal webinars, podcasts, studio-quality interviews.
- Messy conversations: Contact center audio, crosstalk, low-bitrate telephony, background noise.
- Specialized terminology: Medical dictation, legal proceedings, technical demos, policy-heavy support calls.
- Challenging speakers: Different accents, dialects, age ranges, and speaking speeds.
What works: scoring transcripts against your own representative audio library.
What doesn't: choosing a platform because a demo file sounded good.
Fairness is not a side issue
A strong benchmark average can hide uneven performance across speaker groups. That matters a lot in hiring, healthcare, public services, and customer support.
If your organization serves diverse populations, test for dialect handling explicitly. Don't assume “multilingual” or “high accuracy” marketing language covers this. Procurement teams often miss this step, then discover the problem only after complaints or QA failures surface.
Real-World Applications Across Industries
The practical value of speech to text ai shows up when you compare the old workflow to the new one. Before transcription, teams replay recordings. After transcription, they search, flag, route, and act.

Contact centers and customer experience
Before adoption, a QA lead might sample a small slice of calls manually. That approach misses patterns.
Once speech is transcribed, teams can review disclosures, identify repeat objections, route complaints by topic, and support agent coaching with searchable evidence. If you're mapping that use case, Halo AI's overview of applications of AI call analysis gives a useful picture of how review workflows evolve beyond random call listening.
Fairness matters here too. Research covered by Georgia Tech notes that Stanford's FAIRSPEECH project found leading tools can misunderstand Black speakers twice as often as white speakers, which is a direct service-quality risk in customer support, healthcare, and public-sector interactions according to Georgia Tech's summary of minority dialect ASR inaccuracy.
Media, broadcasting, and newsrooms
Media teams usually feel the pain in turnaround speed. Editors need transcripts for rough cuts, quote extraction, accessibility captions, and archive indexing.
Once transcripts are available, a producer can search for a name, topic, or quote instead of scrubbing through a timeline manually. That changes archive value completely. Old interviews, press briefings, and field recordings become usable assets instead of storage costs.
For newsroom-specific workflows, this guide to speech-to-text for media and newsrooms shows where transcription directly affects editorial speed and archive retrieval.
Healthcare, legal, and compliance-heavy teams
These teams don't just need convenience. They need records they can review and defend.
In healthcare, speech to text ai can support documentation workflows where terminology accuracy and review processes matter more than flashy UI. In legal settings, transcripts help teams search testimony, hearings, or interviews quickly, then return to the exact moment in the source audio. In compliance review, searchable transcripts make it possible to verify that required language was used.
Internal operations and knowledge capture
Some of the strongest use cases are less visible. Product teams transcribe user interviews. Research teams transcribe qualitative sessions. Training teams transcribe internal recordings so future employees can search institutional knowledge instead of asking someone to remember where it was discussed.
If your organization records conversations that people later need to revisit, there's usually a transcription use case hiding in plain sight.
Choosing Your Implementation Path
Organizations typically choose between two implementation models: Batch processing for completed files, or real-time streaming for live audio.
The right choice depends less on technical taste and more on business timing. When does the text need to exist?
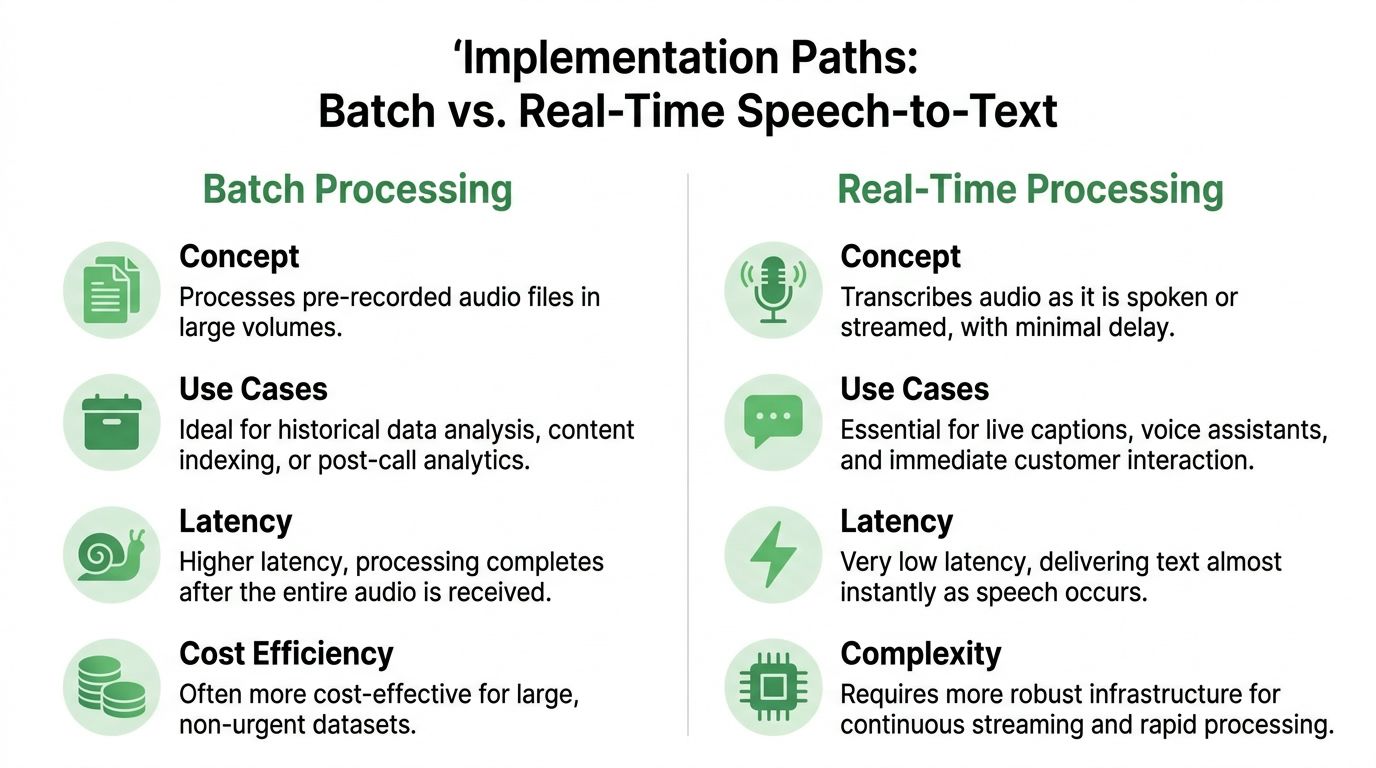
Batch works best when the event is already over
Batch transcription is the cleaner path for pre-recorded media and historical archives. You upload a finished file, process it asynchronously, and retrieve the transcript once the job completes.
This fits workflows like:
- Post-call analytics: Review conversations after the interaction ends.
- Media ingestion: Transcribe interviews, broadcasts, or podcasts after upload.
- Backfile conversion: Turn large libraries of old recordings into searchable text.
- Research and legal review: Process recorded sessions where immediacy isn't required.
Batch systems are often easier to integrate because you don't need to maintain a live audio stream or manage partial transcript events. If the use case is archival, analytical, or editorial, batch is usually the practical default.
Real-time is for decisions that happen during the conversation
Streaming transcription is different. The transcript has to appear while people are still speaking.
That matters for live captions, agent assist, meeting assistance, voice interfaces, and any workflow where the text triggers an immediate action. The engineering trade-off is higher complexity. You need stable stream handling, careful latency management, and downstream systems that can work with partial, evolving transcripts.
A simple comparison helps:
| Decision factor | Batch processing | Real-time streaming |
|---|---|---|
| When text appears | After file upload and processing | During the conversation |
| Best fit | Archives, post-event analysis, media libraries | Live captions, agent assist, voice apps |
| Integration burden | Lower | Higher |
| Tolerance for delay | Usually acceptable | Usually low |
API choices matter more than glossy demos
When developers move from pilot to production, they usually care about the same handful of details: authentication, SDK quality, webhook behavior, streaming stability, speaker separation, timestamps, and error handling.
A good implementation path also leaves room for growth. You may start with basic transcription and later add custom vocabulary, entity extraction, PII redaction, or multilingual workflows. That's where API-first products are often easier to extend than point solutions.
For example, Vatis Tech offers file upload and streaming speech-to-text workflows, along with features such as speaker diarization, timestamps, custom vocabulary, and PII redaction, which are the kinds of capabilities teams typically evaluate when moving from transcription into broader operational use.
Navigating Security and Compliance Guardrails
Security decisions in speech to text ai aren't paperwork decisions. They're architecture decisions.
If your audio contains customer data, health information, payment details, employee conversations, or legal material, the transcription vendor becomes part of your data-handling chain. That means retention, access, processing location, auditability, and training policies all matter before you even compare accuracy.
What to verify before procurement signs off
For regulated industries, compliance is an architectural choice. Buyers should prioritize providers that offer zero-data-retention modes, data-processing agreements, and explicit opt-outs for model training, because retaining or reusing customer audio increases breach, privacy, and cross-border transfer risk, as explained in AssemblyAI's enterprise guidance for speech-to-text procurement.
That guidance lines up with what implementation teams see in practice. If a provider stores audio by default, trains on it without clear boundaries, or can't explain its subprocessors cleanly, legal review gets harder and deployment slows down.
A practical review list should include:
- Retention controls: Can the provider process audio without storing it longer than necessary?
- Training-data policy: Is there a clear opt-out from model training or reuse?
- Auditability: Can your team reconstruct who accessed transcripts and when?
- Data transfer model: Where does processing occur, and how is cross-border handling managed?
- Contractual support: Are DPAs and related terms mature enough for enterprise review?
Accuracy affects compliance more than teams expect
Compliance teams sometimes treat transcription quality and security as separate topics. They're connected.
When transcription quality is weak, downstream systems are more likely to miss sensitive numbers, names, identifiers, or regulated language. That creates gaps in redaction, searchability, evidence review, and disclosure verification.
Better transcripts don't just improve readability. They improve whether masking, redaction, and audit workflows can be trusted.
Security review should include the surrounding stack
A speech-to-text deployment is rarely just one API call. It usually includes storage, queues, event handlers, transcript viewers, exports, and analytics tools. That wider stack needs testing too.
If your team is formalizing security validation around customer-facing systems, it can help to review how white label automated pentesting fits into broader application assurance. The key point isn't a specific security service. It's that transcription pipelines deserve the same scrutiny as any other system processing sensitive data.
What works and what doesn't
What works is selecting a provider whose privacy and retention model already fits the business. What doesn't work is choosing the most convenient API first, then trying to retrofit compliance after legal review finds gaps.
That order matters. When security is built into the architecture, the rollout gets faster. When security is treated as an afterthought, the project often stalls right when stakeholders expect it to go live.
Your Next Steps An Evaluation Checklist
Many teams don't need another vendor feature page. They need a buying process that reduces mistakes.
The best way to evaluate speech to text ai is to treat it as a workflow tool, not a generic model. Brown's CCV Transcribe materials make that point clearly: evaluation must go beyond WER and include speed, latency, domain adaptation, and diarization quality, and teams should test on their own audio conditions and use cases in Brown's comparison guidance for speech-to-text models.
A practical checklist for buyers and builders
Use this sequence when you evaluate vendors or plan an internal pilot.
Define the exact job
Don't start with “we need transcription.” Start with the business event. Is this for post-call QA, captioning, clinical documentation, interview archives, legal review, or a product feature inside your app? The use case determines latency, formatting, compliance, and integration needs.
Collect a representative audio set
Pull examples from real conditions, not just clean recordings. Include noisy calls, overlapping speakers, domain-specific terminology, and different accents or dialects. Weak models reveal themselves under these circumstances.
Score what matters operationally
Review accuracy, but also inspect timestamps, speaker separation, edit effort, turnaround speed, and how often the transcript breaks downstream workflows. A “good enough” transcript for summary generation may be unusable for legal or billing review.
Check implementation fit
Ask whether batch, streaming, or both are required. Then confirm API design, SDK support, error handling, webhook behavior, and export formats match the systems your team already runs.
Review compliance before procurement drift starts
Bring in security and legal early if the audio is sensitive. Confirm retention behavior, training-data policy, access controls, and audit support before stakeholders get attached to a demo.
- How much transcript editing does a user need to do?
- Where does the model fail first, with noise, jargon, speaker overlap, or dialect variation?
- Can the output feed search, redaction, analytics, or captioning without custom cleanup?
- What happens when the workflow scales from a sample set to production volume?
The questions worth asking in a pilot
Some questions separate serious evaluations from surface-level demos:
Selection advice: If you can't test a provider on your own messy audio, you don't really know how it will perform.
What a successful first rollout looks like
A good first deployment is narrow and measurable. Pick one workflow with clear business pain, a known user group, and a review loop. That gives your team enough control to validate output quality, security fit, and operational value before expanding to adjacent use cases.
Speech to text ai delivers the most value when it's tied to a real process. Not “transcribe everything.” Transcribe the conversations that someone needs to search, review, act on, or defend.
If you're comparing options for transcription workflows or API integration, Vatis Tech is one platform to review. It supports speech-to-text for audio and video, offers developer APIs and SDKs, and includes features teams commonly need in production workflows such as diarization, timestamps, multilingual support, and editing tools.




